Single-tenant data models
Table of Contents
A data model pattern is "single-tenanted" to ThoughtSpot if some aspects of the database connection or actual tables are different enough to require separate objects in ThoughtSpot for each tenant, often called logical separation.
Logical separation might be caused by:
-
separate data warehouse credentials or other attributes
-
different databases
-
different schemas
or any other set of attributes that amount to either different connections or different Table objects in ThoughtSpot.
"Prod" environments for single-tenant data models🔗
Rather than a single multi-tenanted "prod" environment, the deployment pattern for single-tenanted customer databases is to have a "release" or "pre-prod" environment and then one Prod Org Per Customer.
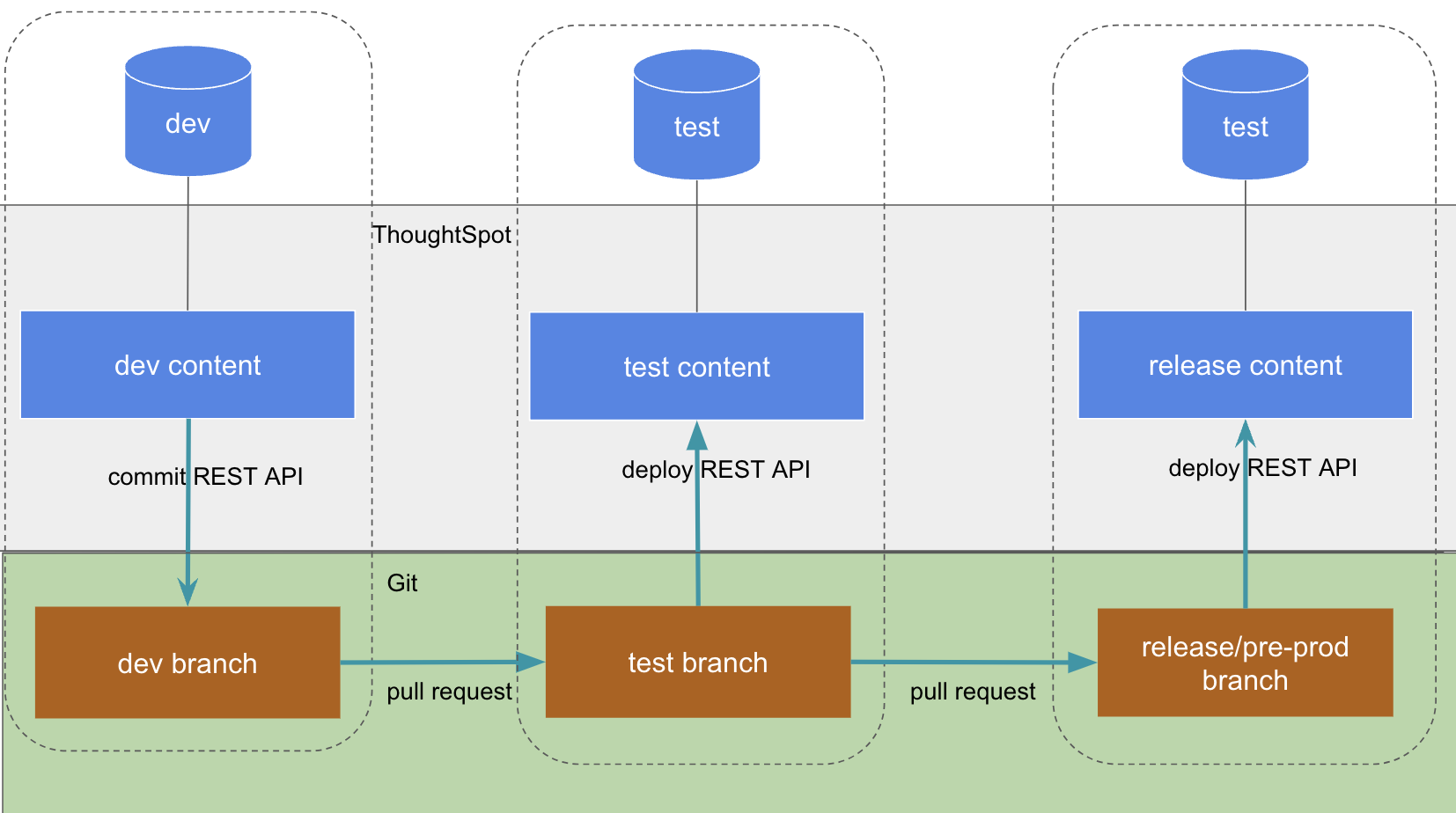
The initial processes and environments resemble a multi-tenanted prod deployment:
Once content has been deployed successfully to the "release" or "pre-prod" Org, then the release to each of the end customer prod Orgs can begin:
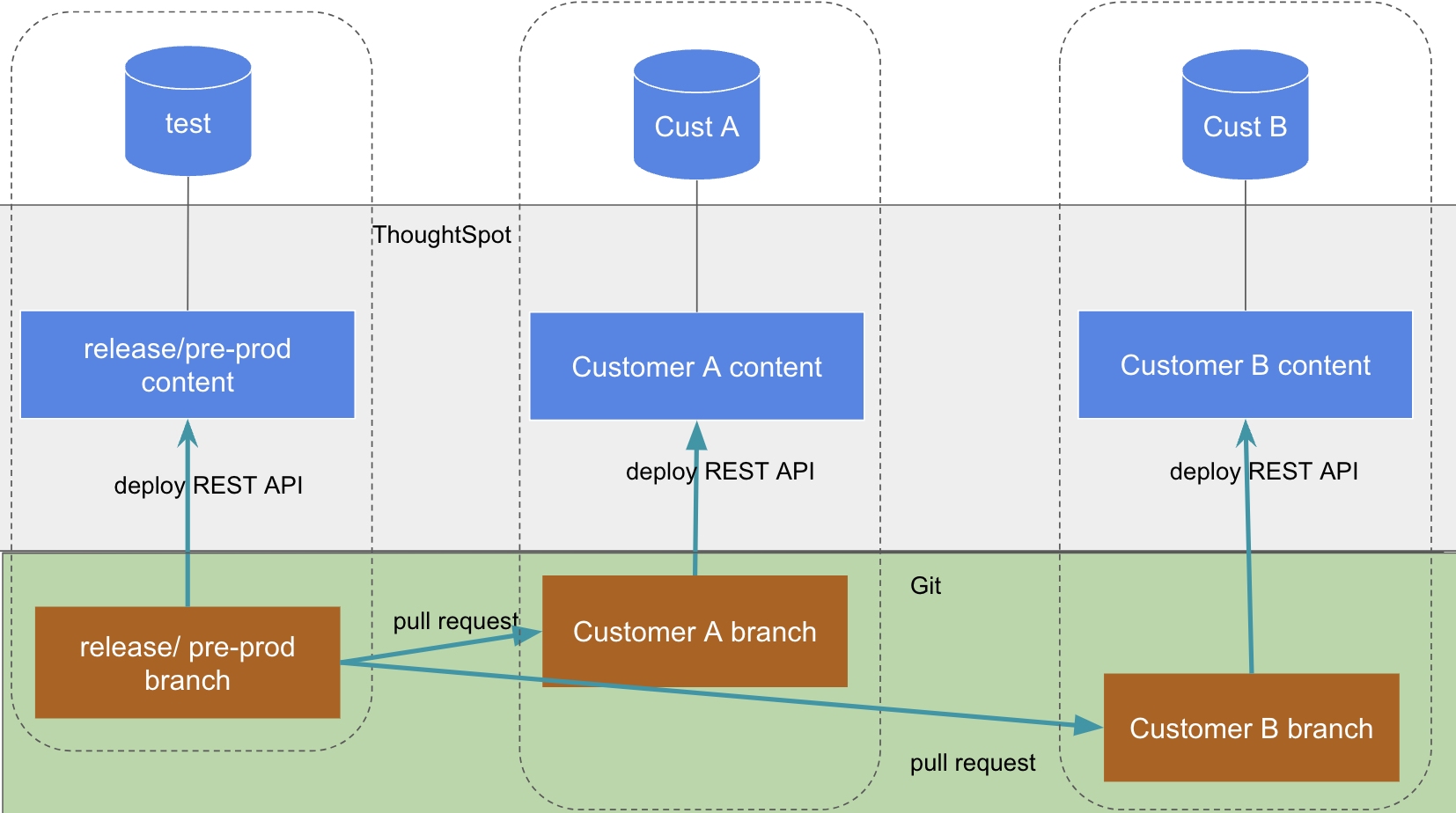
This process is best achieved through using the Git Integration REST APIs, which can support any number of configurations for any number of environments.
Creating environment for each customer🔗
The Orgs administration REST APIs allow an administrator account from the Primary Org to automatically provision each End Customer Org.
Once the Org exists, add the end customer users to the Org along with any desired ThoughtSpot groups via the user and group management APIs.
Finally, create the Git branch to map to the Org to create the environment, and then update the Git configuration via the REST API to tell ThoughtSpot about connection between the Org and the Git branch.
Deploying via Git integration🔗
To make deployment to each of the prod Orgs feasible, utilize the GUID Mapping file for each Org, ensuring that all files are deployed appropriately from the "release" environment with all necessary attributes for the destination environment during the deploy commits process.
Single-tenant data models🔗
The "single-tenant data model" is designed on the following principles:
-
Each customer organization has its own database to connect to, with only that customer organization’s data present when making the database connection. Every database is similar in structure (table names and column names / data types).
-
Multiple customer organizations in ThoughtSpot
-
Content (answers and Liveboards) are provided by the app developer in the form of templates
-
Users within the customer organizations can create their own content and share it with other users within their own organizations
If you have the choice between designing your cloud data warehouse along a single-tenant or multi-tenant model, it will be simpler to implement in ThoughtSpot using the multi-tenant model.
Content provided by app developer🔗
Single-tenant databases require separate connections in ThoughtSpot for each database in most cases. There will then be separate objects on the ThoughtSpot Server for each connection. Because all the objects other than the connection will be very similar, the deployment pattern can be handled through templating: there will be a set of template objects that are deployed for each tenant.
We can describe the template as the parent content, with child objects that descend from the template.
The template content itself will be built by the app developer, but will not be accessible to the customer organizations. Instead, there will be a deployment process that copies the template content, makes the necessary changes, and then publishes it to the appropriate group for each customer.
Content provided by app developer to each tenant group🔗
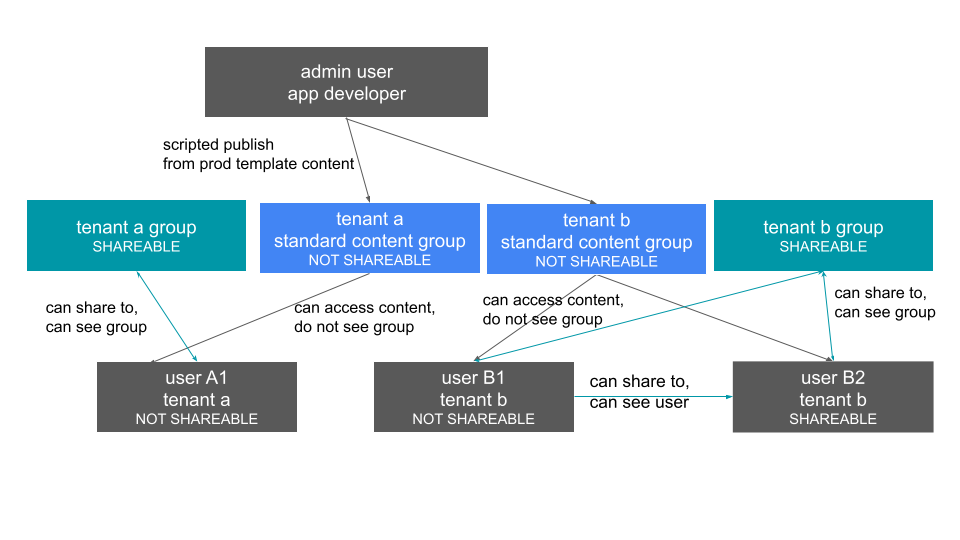
Each tenant should have a group used to give access to the content provided by the app developer—a tenant application group. Only the application developer would publish content to this group, and it should be set to NOT SHAREABLE.
Content belonging to individual tenants🔗
To allow users to create their own content and share only within their organization, you will create at least one group for each tenant, separate from the application tenant group. This group can be set to SHAREABLE, or you may want additional groups below the main tenant group, representing different sets of users who belong to that tenant, and then make those child groups the ones that are SHAREABLE.
Summary of access groups for single-tenant databases model🔗
The following table lists the access groups needed for this model. There will also be privilege groups, data access groups, and development and test content groups. You can name the groups anything you’d like, with a naming scheme that makes sense to you. The "group type" names here are just indications of the purpose of those groups.
Reminder: when a group is set to NOT SHAREABLE, administrators can still share content to that group. NOT SHAREABLE groups are used for the content provided by the app developer to end users.
| Group type | Content shared to group | Users in group | Sharability |
|---|---|---|---|
prod template group | Template Tables, Models, Answers, Liveboards | app developer | SHAREABLE |
standard data groups (1 per tenant) | tables (connected to tenant connection) | app developer | NOT SHAREABLE |
standard content groups (1 per tenant) | Models, Answers, Liveboards | tenant users per group | NOT SHAREABLE |
tenant content groups (1 per tenant) | answers, Liveboards | tenant users per group | SHAREABLE |