from thoughtspot_rest_api import *
username = 'username'
password = 'password'
server = 'https://{instance}.thoughtspot.cloud'
ts: TSRestApiV2 = TSRestApiV2(server_url=server)Complex REST API workflows
Get started🔗
The files for this tutorial are api_training_python_2_begin.py and api_training_python_2_end.py.
You must have installed the thoughtspot_rest_api library in the Python environment you are using, based on the tutorial prerequisites. Despite the name, the library has components for interacting with both the V1 and V2.0 ThoughtSpot REST APIs.
|
Note
|
|
01 - Use ThoughtSpot REST API library🔗
The thoughtspot_rest_api library was originally created because the V1 ThoughtSpot REST API is uniformly structured, so a library with an implementation of each endpoint was created as a reference for formatting and sending each request correctly.
The V2.0 REST API is simple enough to implement in any language. We’ve just completed the initial steps in Python in the previous lesson.
The V2.0 portion of the library implements the repeated standard steps everyone would have to do for themselves each time, and issues can be reported to and fixed in the library once for everyone.
The library encapsulates logic around constructing REST API requests correctly, so that you don’t have to rewrite code.
Endpoints are defined properly, along with HTTP request details and response handling.
Import thoughtspot_rest_api library🔗
Rather than helper functions like in JavaScript, the thoughtspot_rest_api library provides two classes that represent the two REST API versions: TSRestApiV1 and TSRestApiV2.
Classes define how to build Objects, which combine data (called properties) and functions (called methods).
There are methods for each endpoint, typically named identically with the forward slash / replaced by an underscore _: the /metadata/search endpoint becomes the .metadata_search() method.
To get started, let’s import all of the classes from the library and then create a TSRestApiV2 object. This object will be used for all subsequent calls.
02 - Authentication🔗
The TSRestApiV2 object doesn’t automatically log in a user. You must explicitly request an authentication token and set the TSRestApiV2.bearer_token property:
from thoughtspot_rest_api import *
username = 'username'
password = 'password'
org_id = 0
server = 'https://{instance}.thoughtspot.cloud'
ts: TSRestApiV2 = TSRestApiV2(server_url=server)
try:
auth_token_response = ts.auth_token_full(username=username, password=password, org_id=org_id, validity_time_in_sec=36000)
# Endpoints with JSON responses return the Python Dict form of the JSON response automatically
ts.bearer_token = auth_token_response['token']
except requests.exceptions.HTTPError as e:
print(e)
print(e.response.content)
exit()You can also issue a /session/login request with a token or the username/password, and the object will maintain authentication using its internal requests.Session object:
ts.auth_session_login(bearer_token=auth_token_response['token'], remember_me=True)
# or
ts.auth_session_login(username=username, password=password, remember_me=True)You’ll notice that we’ve already accomplished everything we did in the previous lesson with much less code.
03 - Use other endpoints🔗
All of the methods of the TSRestApiV2 class are named after their equivalent REST endpoints, with an underscore character _ replacing the forward slashes / from the URLs.
For example, the /users/search endpoint is accessed via the TSRestApiV2.users_search() method.
If everything is installed and configured properly in your IDE, you should get auto-complete on the available endpoints as you type:
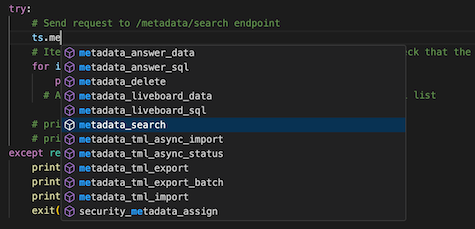
For endpoints that have only a few strictly defined arguments, the method will define Python arguments to match the endpoint’s arguments:
users_delete(user_identifier:str)
Endpoints with many request options simply take a request= argument, which expects a Python Dict matching the JSON request you see in the REST API Playground:
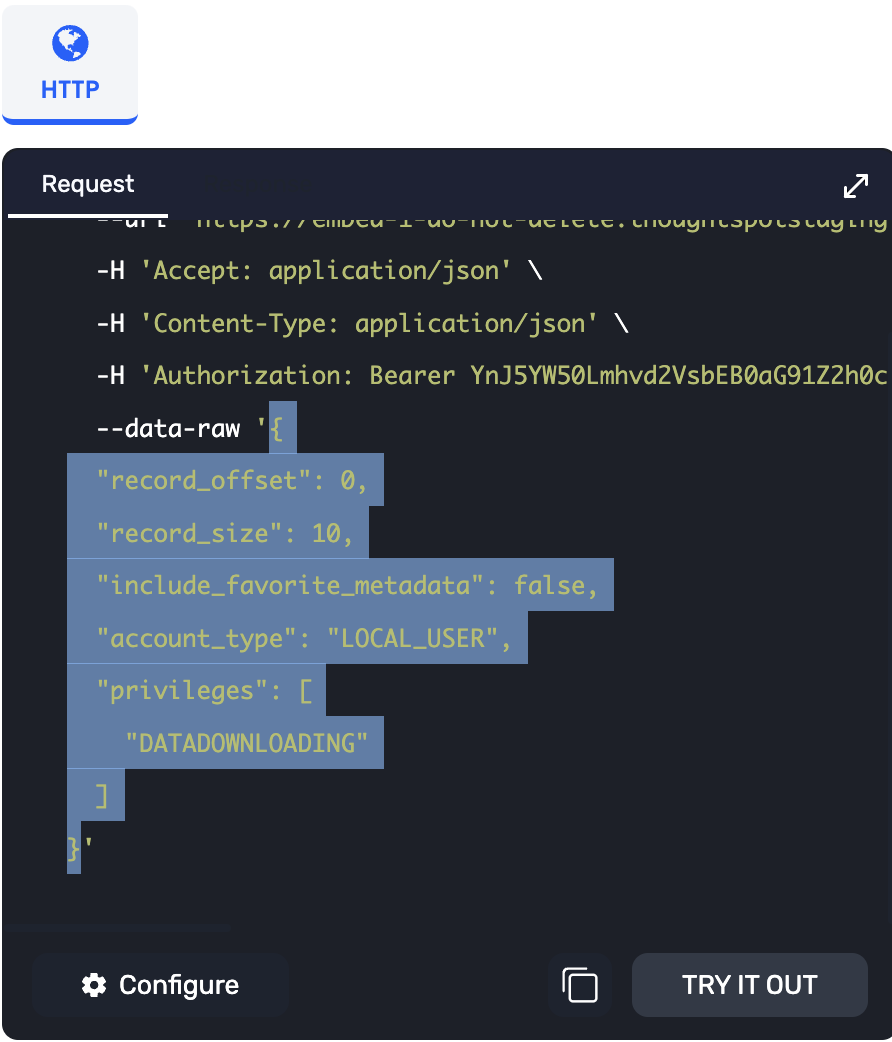
# Get all Users with a particular privilege
search_request = {
"record_offset": 0,
"record_size": 10,
"include_favorite_metadata": False, # make sure to upper-case booleans
"privileges": [
"DATADOWNLOADING"
]
}
try:
users = ts.users_search(request=search_request)
except requests.exceptions.HTTPError as e:
print(e)
print(e.response.content)
exit()
for u in users:
# get details of each table and do further actions
user_guid = u['id']04 - Complex workflows🔗
The real reason to use the library is to allow quickly combining the results of multiple requests into complex and flexible workflows.
We’ll walk through the process of determining the steps for a sample task, and then code the necessary steps.
Our example task is to find all Liveboards and Answers with a name that includes '(Sample)' and tag them with the tag called 'Tutorial Test'.
Define steps🔗
It’s easiest to program by defining the exact requirements, breaking them down into logical steps, and then writing the code accordingly.
Let’s split the task into discrete steps:
-
Find all Liveboards and Answers with a name that includes '(Sample)'
-
Add a tag called 'Tutorial Test' to all of the items
Create comments in your code file to help structure your thinking:
# 1. Find all Liveboards and Answers with a name that includes '(Sample)'
# 2. Add a tag to each item called 'Tutorial Test'Even this basic step opens up new questions as to what our exact requirements are:
# 1. Find all Liveboards and Answers with a name that includes '(Sample)'
# Get all of the items with names including '(Sample)'
# Is this a case-sensitive or case-insensitive operation? Are we finding anywhere in the name or just at start or end?
# 2. Add a tag to each item called 'Tutorial Test'
# Get the ID of the tag called 'Tutorial Test'
# What if there is no tag called 'Tutorial Test'?
# Assign Tag to each itemFind and test endpoints in the REST API V2.0 Playground🔗
As we’ve seen in the previous lessons, the REST API V2.0 Playground is the documentation for the requests and their responses, as well as an interactive system that allows you to run the commands.
|
Note
|
Don’t press |
The first of our tasks is:
# 1. Find all Liveboards and Answers with a name that includes '(Sample)'
# Get all of the items with names including '(Sample)'
# Is this a case-sensitive or case-insensitive operation? Are we finding anywhere in the name or just at the start or end?Information about the objects in the system lives under the Metadata heading within the Playground. Endpoints labeled Search are GET methods that query information without causing any changes.
/metadata/search has many different request parameters available to help filter and select all of the necessary information.
The metadata key takes an array of Metadata List Items, which can have a name_pattern argument along with type. Note that it says "match the case-insensitive name of the metadata object" - if this matters, you’ll need additional code to inspect the result set from the API.
The second task is:
# 2. Add a tag to each item called 'Tutorial Test'
# Get the ID of the tag called 'Tutorial Test'
# What if there is no tag called 'Tutorial Test'?Tags have their own section in the Playground - /tags/search will help us find a tag by a particular name.
Look at the description of the tag_identifier parameter in the request: "Name or Id of the tag". Almost every _identifier argument within the API works this way - it can take an object’s GUID or the name property.
Our comments remind us to consider the situation where the Tutorial Test tag does not exist.
The /tags/create endpoint is available, with the only required option being the name property.
Lastly, we want to assign the tag to the items from the /metadata/search request, minus any additional filtering we do.
Looking at the Assign Tag endpoint:
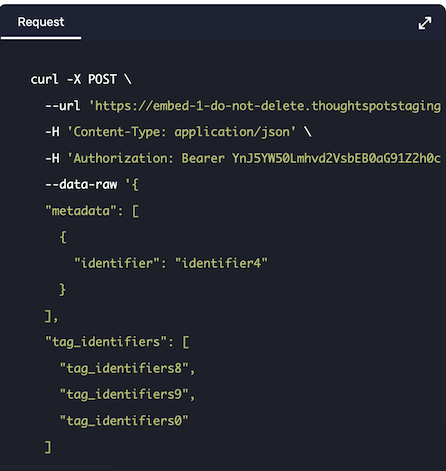
There are two sections, metadata which is an array of objects, each with an identifier key, and then a tag_identifiers array of strings.
Write code🔗
Now that we’ve found our endpoints and looked at the requests and responses, let’s write the code to combine all endpoints into a workflow.
Let’s start with the first step:
# 1. Find all Liveboards and Answers with a name that includes '(Sample)'
# Get all of the items with names including '(Sample)'
# Is this a case-sensitive or insensitive operation? Are we finding anywhere in the name or just at the start or end?
# Create request to /metadata/search to find the Liveboards and Answers matching the name pattern
# Use the Playground to build your request, then copy the code and paste it in the script
search_request = {
"metadata": [
{
"name_pattern": "(Sample)",
"type": "ANSWER"
},
{
"name_pattern": "(Sample)",
"type": "LIVEBOARD"
}
],
'record_offset': 0,
'record_size': 10000
}
try:
# Send request to /metadata/search endpoint
metadata_resp = ts.metadata_search(request=search_request)
except requests.exceptions.HTTPError as e:
print("Error from the API: ")
print(e)
print(e.response.content)
exit()Remember the note about case-sensitivity? We can use Python’s string methods to apply stricter logic than the API provides:
# Create a list to hold the final set of Answers + Liveboards we want to tag and share
final_list_of_objs = []
# Iterate through the results from the API response to double-check that the name value matches exactly
for item in metadata_resp:
m_name = item["metadata_name"]
m_id = item["metadata_id"]
# Python string find is case-sensitive
if m_name.find("(Sample)") != -1:
final_list_of_objs.append(item) # We'll add the whole object to the new list
# optional print to command line to see what happened
print(json.dumps(final_list_of_objs, indent=2))Next, we’ll find the tag to apply using the /tags/search endpoint.
You’ll notice that the autocomplete for the TSRestApiV2.tags_search() method shows defined arguments rather than a generic request argument.
When an endpoint has very few possibilities, the library often has the full set of arguments available directly.
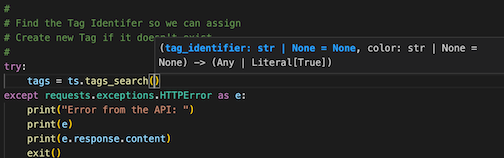
# 2. Add a tag to each item called 'Tutorial Test'
# Get the ID of the tag called 'Tutorial Test'
# What if there is no tag called 'Tutorial Test'?
#
# Find the Tag Identifier so we can assign it
# Create new Tag if it doesn't exist
#
try:
tags = ts.tags_search(tag_identifier="Tutorial Test")
except requests.exceptions.HTTPError as e:
print("Error from the API: ")
print(e)
print(e.response.content)
exit()Next, let’s add the logic to create the tag if none is found with that name. Note that tags_create() also has defined arguments rather than taking a request:
if len(tags) == 0:
try:
new_tag = ts.tags_create(name="Tutorial Test")
tag_id = new_tag['id']
except requests.exceptions.HTTPError as e:
print("Error from the API: ")
print(e)
print(e.response.content)
exit()
else:
tag_id = tags[0]['id']Finally, we’ll take the tag ID and the objects whose names matched and apply the tag.
Let’s go back to the Playground to copy the request. Remember that the metadata section is not a simple array, but an array of objects:
assign_req = {
"metadata": [
{
"identifier": "identifier4"
}
],
"tag_identifiers": [
"tag_identifiers8",
"tag_identifiers9",
"tag_identifiers0"
]
}We’ll need to create the data structure that the metadata parameter needs by iterating through the objects stored in final_list_of_objs, and then assigning that result to the metadata parameter’s value:
# Assign the tag to the items
try:
# When we copied from the Playground, the format of the `metadata` section is an array of objects,
# which needs to be a list of Dicts in Python syntax [ {"identifier": metadata_id}, ...]
tag_metadata_section = []
# Iterate through each object and construct the Dict in the correct format
for obj in final_list_of_objs:
tag_metadata_section.append({"identifier" : obj['metadata_id']})
assign_req = {
"metadata": tag_metadata_section,
"tag_identifiers": [tag_id]
}
assign_resp = ts.tags_assign(request=assign_req)
except requests.exceptions.HTTPError as e:
print("Error from the API: ")
print(e)
print(e.response.content)
exit()05 - Conclusion🔗
After completing these lessons, you should be very capable at using the REST API V2.0 Playground and the thoughtspot_rest_api library to retrieve and process the results of the /search endpoints and then issue other commands using the IDs of objects.
By moving hard-coded values into variables, you can develop reusable scripts to accomplish tasks that otherwise would require a lot of manual effort.
There are many existing examples of workflows that can be pieced together to accomplish any number of administration and integration tasks.