Deploy with TML APIs
Table of Contents
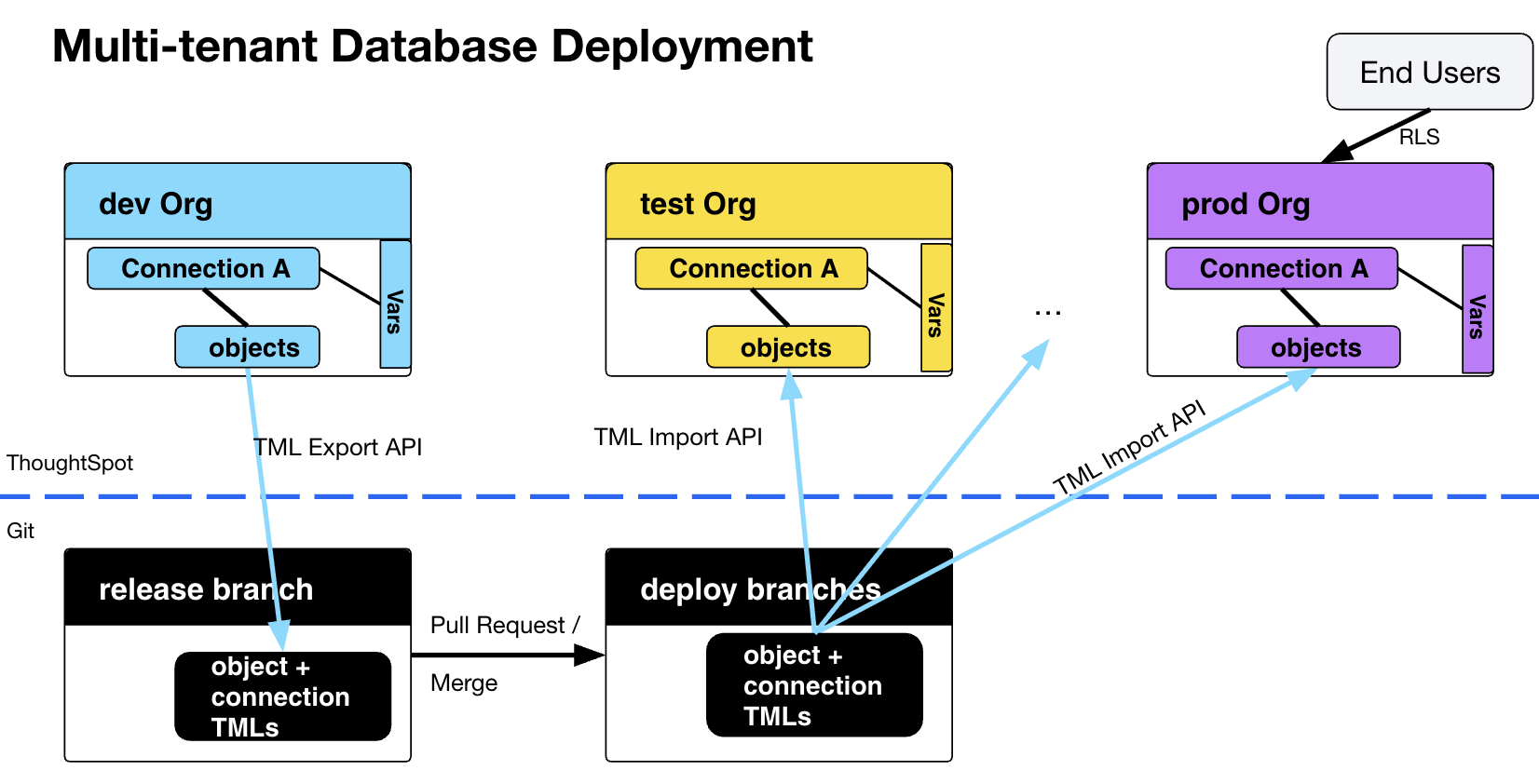
When deploying embedded analytics, each organization will have defined practices for development, testing, and deployment of content to ThoughtSpot. ThoughtSpot instances act as a constantly running service, so deployment only involves publishing ThoughtSpot content, in the form of ThoughtSpot Modeling Language (TML) files to a given ThoughtSpot instance.
The most typical pattern with ThoughtSpot involves a dev Org where content is modified by the team and then those objects are marked to form a "release" package, which then have their TML exported into a "release" branch in Git:
The TML files in the "release" branch are then moved into other "deployment branches" via pull/merge request.
Other ThoughtSpot Orgs are "deployed to" by importing TML from their designated "deployment branch".
The formalized release process is separate from version control, which is concerned with capturing all changes of all content in a given Org.
Overview🔗
The three steps to building an SDLC process with ThoughtSpot are:
-
Identify objects for release: Determine which objects in "dev Org" should become part of the "release" package
-
Export release TML into Git: Downloading ThoughtSpot objects as TML files into a source control system (for example, Git)
-
Import release: Importing the TML files into the new environment
Pre-requisites🔗
For TML files to be portable between any Org on any instance, the objects must have obj_ids and all Table and Connection objects must have been parameterized with the appropriate variables where necessary.
Once these pre-requisites are complete, your TML will be ready for TML Import across Orgs or publishing:
obj_id: My_Connection__DATA_CHALLENGE__SALES
table:
name: SALES
db: ${dc_db}
schema: ${dc_schema}
db_table: SALES
connection:
name: My Connection
obj_id: My_ConnectionParameterization with variables🔗
In a single-tenanted database pattern, customer data is split into many separate logical databases or schemas, typically with identical table structures.
Queries for each customer can be identical by parameterizing the attributes that vary. ThoughtSpot provides variables that can be referenced in TML for this purpose.
Details about the fully-qualified table name are stored in each Table object in ThoughtSpot, rather than in the Connection object. The following can be parameterized in a Table TML file:
-
database
-
schema
-
db_table_name
Properties of a Connection can also be parameterized.
Parameterization works with both TML import and publishing.
obj_id🔗
Before implementing any deployment process, you should ensure that obj_id is enabled on your ThoughtSpot instance.
|
Note
|
Objects are only assigned automatic |
obj_id for an object is available in the response from /metadata/search REST API as metadata_obj_id property:
{
"metadata_id":"c1e4043a-4524-4fcb-a20f-9e7aff4dc972",
"metadata_name":"Retail Sales RAD - KPIs",
"metadata_type":"LIVEBOARD",
"metadata_obj_id":"RetailSalesRAD-KPIs-c1e4043a"
}The format of obj_id above, with the -{startOfGUID} portion at the end, indicates it was an auto-generated obj_id. If the property value was null, then it is an object that has not been updated since the feature was enabled.
The metadata/update-obj-id REST API endpoint can change an object’s obj_id property based on either the metadata_id (GUID) or the current metadata_obj_id:
{
"metadata": [
{
"metadata_identifier": "c1e4043a-4524-4fcb-a20f-9e7aff4dc972",
"new_obj_id": "RetailSalesRAD-KPIs"
}
]
}or
{
"metadata": [
{
"current_obj_id": "RetailSalesRAD-KPIs-c1e4043a",
"new_obj_id": "RetailSalesRAD-KPIs"
}
]
}The request format for metadata/update-obj-id is an array, allowing for updating a large number of objects at once.
Implementing obj_id in existing environments🔗
Once you have decided on the appropriate obj_id for all the objects in your dev Org, you can use any existing GUID Mapping files to update the obj_id values for the equivalent objects in all your other Orgs.
You only have to do this process for existing objects one time, and from that point forward, you can update objects in any Org using TML with obj_ids rather than GUIDs.
Identifying release package in dev Org🔗
The set of objects on the dev Org that makes up the "deployed releases" should be identified in a way that allows easy identification of the objects to be exported into Git.
The following mechanisms can be used to easily identify subsets of objects in an Org:
-
Tags
-
Content Author
-
Collections (if enabled)
The most typical practice is to add a Tag, something like release or rc, to any object that should be exported into the "release" branch.
You can add multiple tags, if you’d like to add tags indicating versioning along with the release indicator.
The /metadata/search REST API endpoint has parameters to filter on tag_identifiers and created_by_user_identifiers. The response from /metadata/search can be processed further to reduce down to the desired list of object IDs to pass to the /metadata/tml/export endpoint.
{
"metadata": [
{
"type": "LIVEBOARD"
}
],
"tag_identifiers": ["release"],
"sort_options": {
"field_name": order_field,
"order": "DESC"
},
"record_size" : -1,
"record_offset": 0
}The author property of an object in the REST API is the value that the created_by_user_identifiers parameter in the /metadata/search endpoint filters on. author can be reassigned from the original creator via the /security/metadata/assign endpoint.
TML Export with obj_id and variables🔗
The process for exporting TML files into source control is:
-
Use Metadata Search REST API /metadata/search to get a filtered list of objects for the release
-
Use
/metadata/tml/exportendpoint withformattype=YAMLto retrieve the TML of the object -
Save the TML response strings to disk in a Git-enabled directory using a consistent name format based on the
obj_id
Best practices with TML export API🔗
The /metadata/tml/export endpoint has many options for controlling the format of the response.
YAML or JSON🔗
The formattype argument can be set to YAML or JSON.
Export in YAML for saving to disk for use in Git or when using the thoughtspot_tml library, which is designed to handle the TML YAML format.
Export in JSON when you need details from TML within a web browser or just need to read values programmatically.
obj_id or guid🔗
Once all your objects have defined obj_id properties, the ideal TML Export setting has the following options (you may have more or others as well):
{
"edoc_format": "YAML",
"export_associated": false,
"export_fqn": false,
"export_options": {
"include_obj_id": true,
"include_obj_id_ref": true,
"include_guid": false
}
}"include_obj_id": true specifies the obj_id at the top of the YAML file as the identifier for the object.
"include_obj_id_ref": true specifies that any related objects referenced in the TML file have an obj_id property as well.
The TML will end up looking like:
obj_id: My_Connection__DATA_CHALLENGE__SALES
table:
name: SALES
db: ${dc_db}
schema: ${dc_schema}
db_table: SALES
connection:
name: My Connection
obj_id: My_ConnectionIf any of the objects do not have obj_id set, the TML will be exported with the guid property at the top, or the fqn: property for a reference, which will be the referenced object’s GUID:
guid: c1e4043a-4524-4fcb-a20f-9e7aff4dc972
table:
name: SALES
db: ${dc_db}
schema: ${dc_schema}
db_table: SALES
connection:
name: My Connection
fqn: 75b717da-94b6-42ae-ab93-110c677703fbexport_associated🔗
The export_associated argument retrieves the TML objects for all related objects when used, including the GUID of each object within the headers. This is useful for dependency checking, but results in longer request times and bigger responses, and possibly exporting the same object over and over.
File and directory naming pattern🔗
obj_id must be unique within an Org, which makes it the obvious value to use as part of the filename of the YAML file on disk. ThoughtSpot’s default file name pattern also includes the object type in the filename, resulting in a suggested pattern:
{obj_id}.{object_type}.tml
You may also want to store various object types in their own directories on disk for ease of organization.
The obj_id should be the first line of any TML file, and the object type should be the second, so you can easily build the filename from the edoc response from the TML Export REST API like:
if 'edoc' in yaml_tml[0]:
lines = yaml_tml[0]['edoc'].splitlines()
if lines[0].find('obj_id: ') != -1:
obj_id = lines[0].replace('obj_id: ', "")
else:
# Exception path of your choice
obj_type = lines[1].replace(":", "")
# Save the file with {obj_type}s/{obj_id}.{type}.{tml}
# Feel free to change directory naming structure to not have 's' at end
directory = "{}s".format(obj_type)
filename = "{}/{}.{}.tml".format(directory, obj_id, obj_type)TML Import with obj_id and variables🔗
The /metadata/tml/import REST API endpoint is used to upload any number of TML files at one time.
All details of the objects to be created or modified are specified within the uploaded TML file, matching first on obj_id and then on guid if obj_id is not present.
If no match is found for obj_id or guid, a new object is created, with the obj_id specified in the TML file (guid will be auto-assigned).
TML import options and responses🔗
Import related TML files together🔗
ThoughtSpot does not consider object display name for a TML file, but does use name matching for data object references within a TML file.
All data objects are referenced as "tables" within TML, whether they are a ThoughtSpot Table, Model, View, SQL view, or any other data object type.
The following heuristic is used to find matching objects by name within tables or joins sections:
-
obj_idwithin other files in the same TML Import operation or existing objects in the Org -
Data object names within the same TML Import operation: Must only be one single object with that name
-
Searches the entire ThoughtSpot Org: Must be only one single object with that name
For this reason, we recommend importing Tables and Models from the same Connection in the same Import TML request, at least on the initial import.
Rules for create vs. update operations🔗
Object names are never used for determining an object to update, because object names are not unique within ThoughtSpot.
Whether an imported TML will create a new object or update an existing object depends on:
-
the presence/absence of the obj_id: property in the TML file
-
the presence/absence of the guid: property in the TML file
-
whether that GUID matches an existing object on that ThoughtSpot instance
-
the
force_create=trueparameter
Creation vs. update is determined by the following rules:
obj_id is always considered first if present. ThoughtSpot looks at org_id + obj_id to find any existing object in that Org with a match, then creates a new object if one is not found
If only GUIDs are in the TML file, without obj_id, the rules are:
-
No GUID in the TML file: always creates a new object with a new GUID
-
GUID in TML file, where an object with the same GUID already exists in instance: update object
-
GUID in TML file, where no object with same GUID exists in ThoughtSpot instance: creates a new object with the GUID from the TML file
-
force_create=true parameter of the TML Import API is used: every uploaded TML file results in new objects being created
Table objects match on the real existence of the table in the particular database:
-
Table objects match on fully-qualified tables in the database (each Connection can only have one Table object per table in the database), not GUID or obj_id: If a Table object representing the same database table is found, the obj_id/GUID of the original object is maintained, but the updates are applied from the new TML file
Additional Resources🔗
-
The thoughtspot_tml library is written in Python providing classes to work with the TML files as Python objects. You can install it via pip:
pip install thoughtspot_tml
-
The thoughtspot_rest_api library is a Python library implementing the full ThoughtSpot REST API. You can install it via pip:
pip install thoughtspot_rest_api