Snowflake Snowpark Predictive Churn Analysis
In this project, we use Snowflake, Snowpark Python, and machine learning to predict customer churn and forecast user engagement patterns. We dive into customer demographics, show data, and subscription information to uncover insights that guide strategic decisions.
Installation instructions
Churn Prediction
1. Connection Establishment
We kick off by establishing a connection to the Snowflake database using Snowpark Python.
2. Data Selection
We curate customer demographics, shows, and subscription data from Snowflake for a comprehensive analysis.
3. Data Preprocessing
Before diving into machine learning, we perform crucial data preprocessing steps:
- Calculated Columns: Create a churn column using open and close date columns.
- Feature Engineering: Transform existing columns like view duration to derive meaningful insights.
- Data Cleaning: Tidy up the dataset by handling missing values, ensuring consistency, and imputing null values strategically.
- Encoding: Prepare the data for model training by encoding categorical columns.
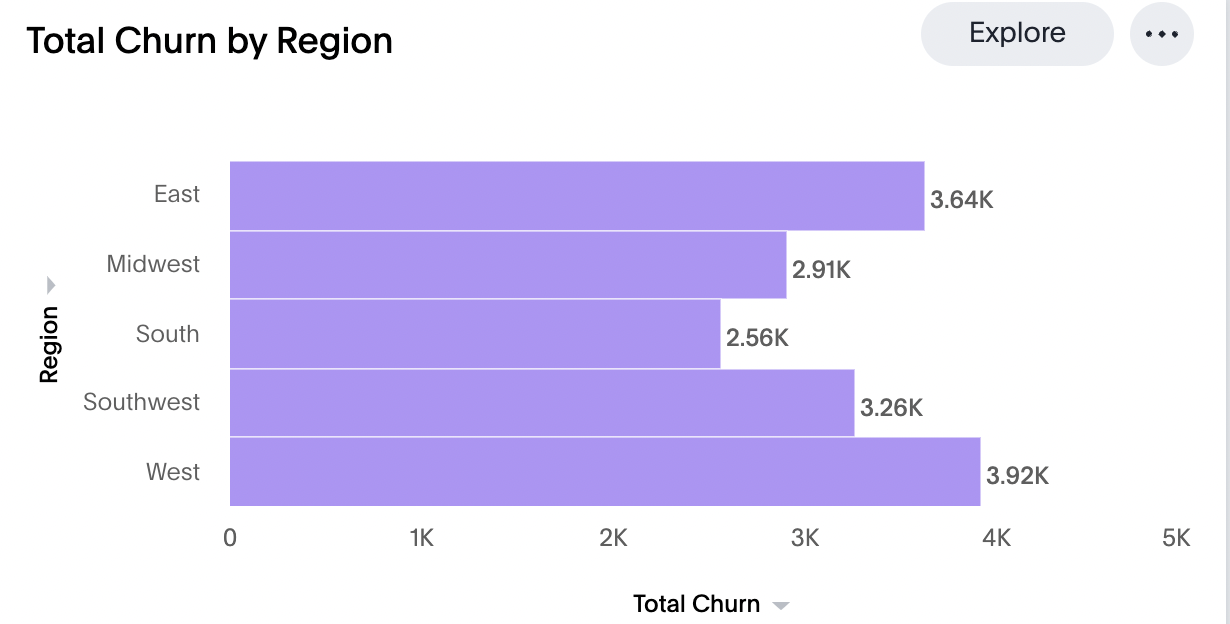
4. Discover who's sticking around and who's saying goodbye
5. Feature Selection and Model Training
Prior to training machine learning models, we conduct feature selection using chi-square test. The selection is based on significant columns identified through chi-square testing. Finally, we train a Random Forest model, evaluating performance metrics like MSE and R2.
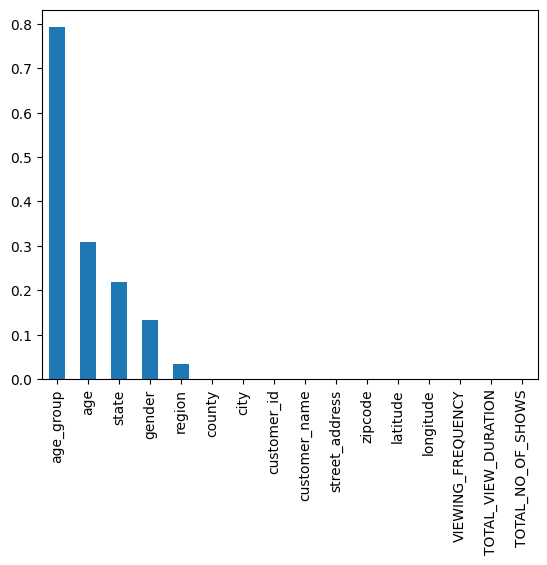
6. Exploring Features
Dive into the impact each feature adds to our churn prediction game:
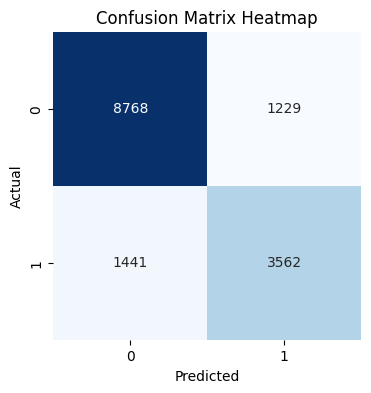
Heatmap of Confusion Matrix: It's a glimpse into the accuracy and missteps of our churn predictions.
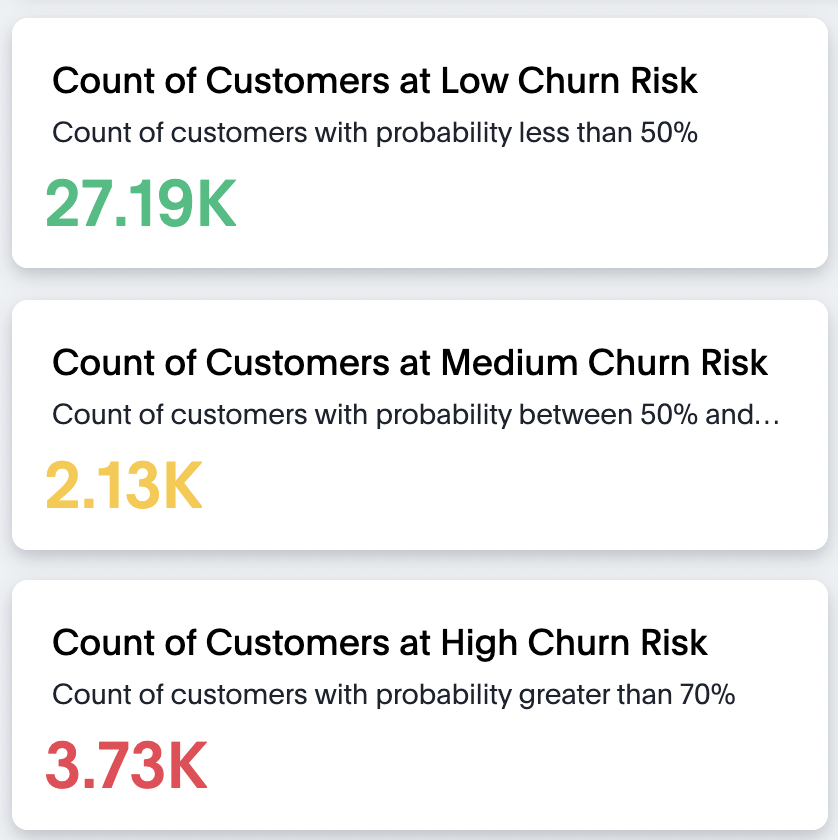
The Churn Risk Spectrum: We're not just predicting churn; we're classifying risk levels! Low, medium, or high.
For detailed instructions, please refer to CF_Churn_prediction.ipynb on GitHub.
Time Series Forecasting
1. Connection Establishment
Similar to churn prediction, we establish a seamless connection to the Snowflake database using Snowpark Python.
2. Data Selection
For time series forecasting, we focus on historical customer and subscription data, preparing it for in-depth analysis.
3. Data Transformation and Aggregation
Transforming Snowflake data into a Pandas DataFrame, we aggregate based on 'view date' and derive additional insights such as the days a customer spent before leaving the platform.
4. Model Selection and Tuning
Choosing the XGBoost Regressor for its prowess in handling intricate data relationships, we fine-tune parameters like the learning rate, maximum depth, and number of estimators.
5. Streamlined Training and Forecasting
To streamline the entire process, we implement functions for creating datasets at the customer level, training models, and forecasting for various time periods.
6. Forecast for Next Month
A sneak peek into the future of Spotflix:
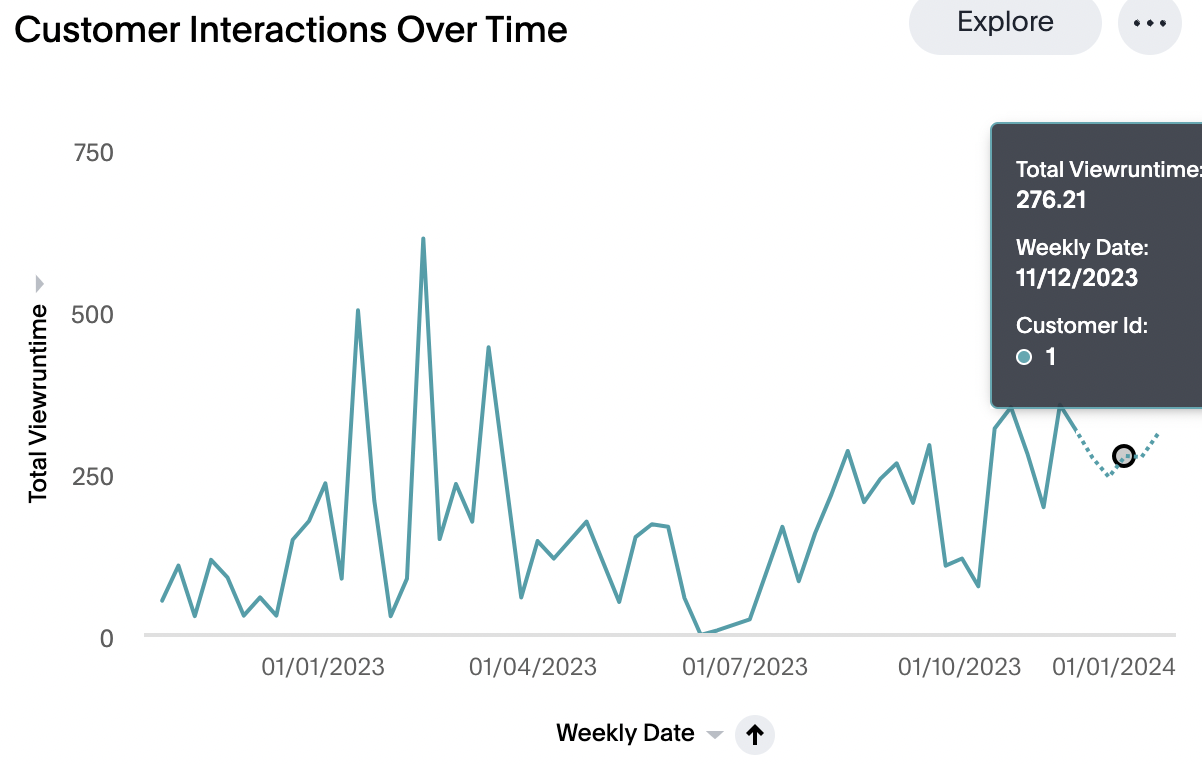
Now our XGBoost model is ready to start forecasting customer viewing patterns for the next 6 months or 1 year. This will give us crucial insights to make better decisions.
Witness how we predict engagement levels and pinpoint those high-risk viewers:
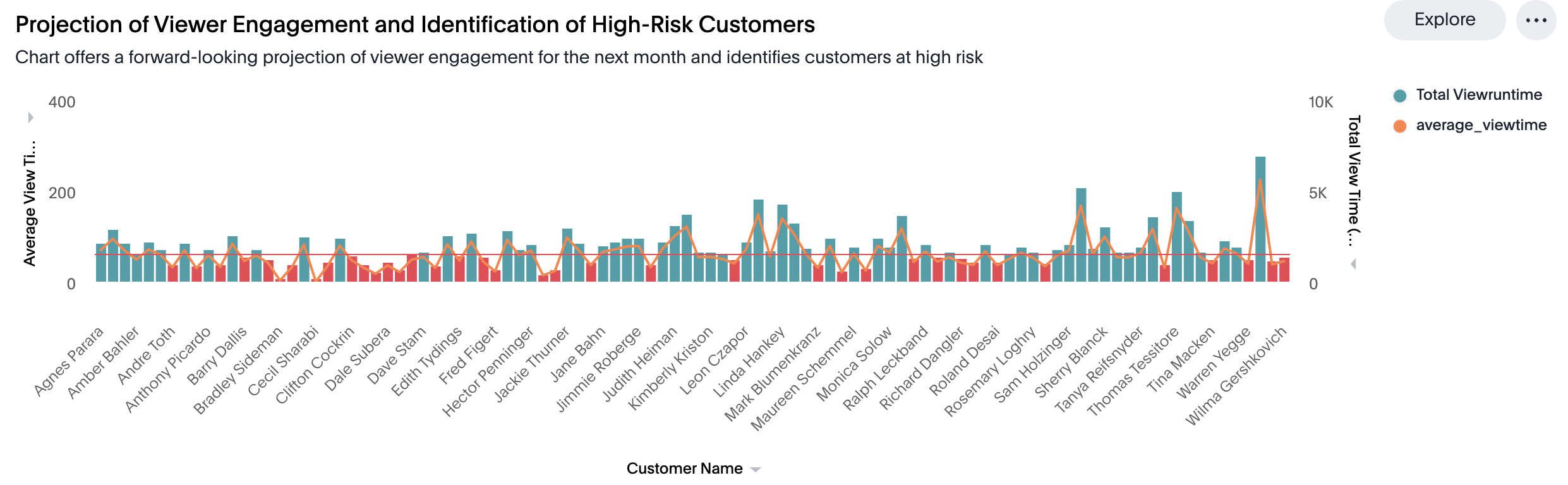
For detailed instructions, please refer to CF_time_series_forecasting.ipynb on GitHub.
Guide to use .tml files
For step-by-step instructions on how to import .tml files into your ThoughtSpot cluster, please refer to How to use TML files.

ThoughtSpot is the Search & AI-driven Analytics platform for the enterprise. Anyone can use search to analyze company data in seconds and get automated insights when you need them.


